


現在位置:
- トップ

- ワークステーション
- CERVO Deep for Linux(Xeon CPU)
- CERVO Deep for Linux Type-DP4U8QR
CERVO Deep for Linux Type-DP4U8QR
深層学習向けワークステーション(最大 8GPU 対応)



3週営業日~出荷3 年間センドバック方式ハードウェア保証
オペレーティング・システム
Ubuntu 18.04 LTS
統合開発環境
CUDA10 / Python / TensorFlow / Keras / Chainer 他
プロセッサー
[2 基] インテル® Xeon® Silver 4110 プロセッサー
メモリー
192GB (16GBx12) DDR4-2666 Registered-ECC
ストレージ
480GB エンタープライズ SSD + [RAID6] 12TB (2TB x8) エンタープライズHDD
光学ドライブ
非搭載
ネットワーク
[2 ポート] 10 ギガビット・イーサーネット
IPMI
[1 ポート] Intelligent Platform Management Interface v.2.0
GPU (計算用)
[8 基] NVIDIA® Quadro® GP100 16GB HBM2
電源ユニット
[冗長化] 2,000W/200V | 1,000W/100V | 80 Plus Titanium 認証
- 販売価格14,069,000円(税込)
「APPLIED CERVO Deep for Linux Type-DP4U8QR」は、深層学習 (Deep Learning) 向けに設計された HPC 専用ワークステーションです。ワークステーションを構成する部材は、すべて「高耐久」「高品質」仕様で、3 年間のセンドバック方式ハードウェア保証となっています。国内(福岡市)の自社工場で企画・製造し、12 時間の品質・動作・エージング検査済みです。
本モデルは、ディープ・ラーニング(深層学習)向けに最適化された OS (Ubuntu 18.04 LTS)、フレームワーク、ライブラリをあらかじめインストールしており、深層学習を意識した専用モデルとなります。最大 8 基までの GPU を搭載でき、全ての GPU が PCI Express switch を通じ 1つの CPU に直結しているため、2 つの CPU に 4台づつ接続する製品よりも、GPU間通信のレイテンシ(通信時間の延滞)が大幅に削減されます。 GPU 間通信を多用するデータ サイエンティスト、研究者、エンジニアは、次の AI ブレイクスルーを生み出すことに時間を費やせるようになります。
GPU(計算用)には、NVIDIA® Quadro® GP100 を標準採用しています。3584 基の CUDA コアと、従来の2倍高速で大容量 16GB の HBM2 メモリによるデータアクセス速度により、倍精度演算性能が 5.2TFLOPSと、飛躍的な向上を実現しました。これにより GPU 間で膨大なデータ通信を必要とする用途にて、データセンタークラスの GPU パワーを実現します。
おすすめポイント
Ubuntu 18.04 LTS
動作検証済

統合開発環境
セットアップ済

インテル Xeon®
スケーラブル 2 基

AVX-512
ベクトル演算

最大 6TB メモリ
6 チャンネル駆動

耐久 SSD
MTBF:200 万時間

エンタープライズ
ストレージ

最大 24 基
ホットスワップ対応
最大 4 GPU
疑似 PCIe 128 レーン

10 ギガビット LAN
2 ポート
IPMI 2.0

高変換効率
80 Plus Gold 認証
4U 19インチ
ラックマウント対応

3 年間 センドバック
ハードウェア保証
国内自社工場(福岡市)で熟練エンジニアによる生産

BTO パソコン・HPC 製品を構成する部材は、自社品質基準をクリアしたものだけを採用しています。 高い性能と耐久性を求められる HPC 製品はもちろんのこと、一般事務などで利用される BTO パソコンについても、安心してご利用いただけるように、部材採用選定から製造まで、一貫して品質向上に努めています。 また、部材供給メーカーや国内正規代理店とも、定期的な品質ミーティングを行っています。
業界屈指の診断ツール「QuickTechProfessional」による品質検査
国内自社工場(福岡市)で生産される BTO パソコン・HPC 製品は、業界標準検査の「QuickTech Professional」による診断を行っています。 プロセッサー、メモリー、ストレージ などコンピューターを構成する各ハードウェアに対し、実際に稼動している時と同じ状態を再現し、負荷検査を行います。
それぞれのハードウェアに対し、個別の強力な診断プログラムが用意されています。 (※ 例えば、メモリの診断では定評あるメモリ診断アルゴリズム「Jump」をはじめ、6 種類の診断アルゴリズムを駆使してエラーを検出します。)
こうして、ソフトウェア的に負荷をかけることにより、従来の診断ツールでは発見できなかったエラーの検出も可能になりました。 この「QuickTech Professional」で診断された結果を「診断書」として製品に添付いたします。これが、「品質合格の証」です。

深層学習 (Deep Learning) に最適化された開発環境

ディープ・ラーニングとは、CUDA を使った深層学習研究、多層構造のニューラルネットワークを用いた機械学習の手法の 1 つです。インプットした情報が第 1 層からより深い層に次々と伝達される間に各層で学習が繰り返されて、その過程で特徴量が自動で計算されていくことで、パターンの認識精度が向上するなど、様々な問題の解決に繋がると期待されています。
本モデルは、ディープ・ラーニング(深層学習)向けに最適化された OS (Ubuntu 18.04 LTS)、フレームワーク、ライブラリをあらかじめインストールしており、深層学習を意識した専用モデルとなります。
ハードウェアの安定動作のみならず、Linux OS や 開発環境の動作を代行して、高品質・安定動作する HPC 専用ワークステーションをご提供します。
CUDA10 / Python / TensorFlow / Keras / Chainer 他
環境構築済みで届いたその日から
インストールしたばかりの OS にDeepLearning用 のセットアップを 1 から行うのは非常に時間と手間のかかる作業です。 また、フレームワークやライブラリのバージョンの違いによって正常に動作しない場合もあり、可能な限り最新のものを使いつつ整合性の取れた組み合わせでセットアップを行うのは至難の業です。
アプライドの CERVO Deep for Linux シリーズは、出荷時にディープラーニング環境を構築済みなので、届いたその日から研究・開発に着手することが可能です。 付属のシステムマニュアルには、代表的なフレームワークライブラリのサンプルプログラムの動作確認手順も記載されているので、ディープラーニングが初めての方にも安心です。

[最大 8 枚] NVIDIA® Quadro® GP100 16GB-HBM2

NVIDIA® Quadro® GP100 は、 最新の NVIDIA Pascal™ アーキテクチャ採用のGPUを搭載した、ウルトラハイエンドグラフィックスボードです。
32bit 単精度浮動小数点演算 CUDA コア 3,584 基、64bit 倍精度浮動小数点演算 CUDA コア 1,792 基を搭載し、倍精度で 5.2TFLOPS、単精度で 10.3TFLOPS、半精度は 20.7TFLOPSと高い性能を実現します。
マルチ GPU 構成に対応した「PCI-Express ブリッジチップ」を搭載
最大 8 基までの GPU を搭載でき、全ての GPU が PCI Express switch を通じ 1つの CPU に直結しているため、2 つの CPU に 4台づつ接続する製品よりも、GPU間通信のレイテンシ(通信時間の延滞)が大幅に削減されます。
GPU 間通信を多用するデータ サイエンティスト、研究者、エンジニアは、次の AI ブレイクスルーを生み出すことに時間を費やせるようになります。
耐障害性を確保する冗長化電源ユニット
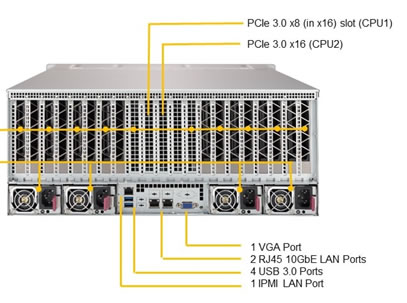
100V 時に 1,000W、240V 時に 2,000W に対応した電源ユニットを 2x2 個搭載しています。万が一、1 台の電源ユニットが故障しても、もう 1 台の電源ユニットが継続して電源を供給することができる冗長性を確保しています。また、ワークステーションを継続運用するための電力を充分に供給できるため、継続して長時間の計算を実行できます。
[2 基] インテル® Xeon® スケーラブル・プロセッサー 搭載 (Skylake)
インテル® Xeon® スケーラブル・プロセッサーは、データセンター・コンピューティング、ネットワーク、ストレージに求められるハードウェア支援型のパフォーマンスが得られます。既存の Skylake と比べ、1 コアあたり L2 キャッシュ容量が従来の 256KB から 1MB へと 4 倍増加しています。レイテンシの少ない L2 キャッシュが増加することで、並列処理の性能が大きく向上します。
インテル® Xeon® スケーラブル・プロセッサーは、Platinum/Gold/Silver/Bronze のラインナップで構成されています。最上位の Platinum では 2.5GHz/tb3.8GHz で最大 28 コア / 56 スレッドで、2/4/8 ソケット構成をサポート、最大 1.5TB の DDR4-2666 に対応します。高度な分析、シミュレーションとモデリング、人工知能に対応して最適なパフォーマンスを発揮します。
Gold は最大 22 コア / 48 スレッドを用意し、2/4 ソケット構成をサポート、効率性と俊敏性に優れたワークロードに最適します。Silverは最大 12 コア / 24 スレッドで、中程度のタスク向けに最適化され、Bronzeは最大 8 コア / 16 スレッドで、軽量なタスク向けに最適化されています。

512 ビットの超広域ベクトル演算機能によるパフォーマンスの向上

512 ビットの超広域ベクトル演算機能を備えたインテル® AVX-512 は、極めて要求の厳しい演算タスクを処理できます。
アプリケーションは、最大 2 つの 512 ビット融合積和 (FMA) ユニットを使用して、クロックサイクルごとに 1 秒当たり 32 個の倍精度浮動小数点演算と 64 個の単精度浮動小数点演算を 512 ビットベクトルにパックすることができ、8 個の 64 ビット整数と 16 個の 32 ビット整数もパックできます。
これにより、インテル® アドバンスト・ベクトル・エクステンション 2.0 (インテル® AVX2) に比べ、データレジスターの幅、レジスターの数、FMA ユニットの幅が倍増します。
最大 6TB / 6 チャンネル 構成に対応した Regeistered-ECC メモリー
最新の DDR4 メモリで、最大 2,933MT/s の高速化に対応しています。また、16 スロットで 、3DS ECC RDIMM の場合は最大 6TB メモリ、3DS ECC LRDIMM の場合は最大で 6TB メモリを実装できます。(プロセッサー仕様に依存します)
1CPU あたり 6 スロット以上を利用することで、最大 6 チャンネルのメモリ帯域が利用でき、通信速度が向上します。
Registered-ECC 機能により、電気信号の清流・増幅で安定したメモリ・アクセス、専用チップでのエラー訂正による信頼性の向上を図っています。

最大 2TB インテル® Optane™ Persistent Memory

インテル🄬 Optane™ DC Persistent Memory は、メイン・メモリーとして一般的に使われる DRAM と同様に、メモリーチャネルと DIMM ソケットを介してアクセスできる不揮発性メモリーです。
大容量メモリ または高速ストレージとして利用でき、現状の DRAM では実現できない大容量のメモリー空間、他の不揮発性メモリーよりも高速なアクセスをご提供します。
※ 第 2 世代 インテル® Xeon® スケーラブル・プロセッサー (Cascade Lake) のみ対応。
運用コストを低減する IPMI 2.0
OS に依存せずに動作する IPMI 2.0 に対応した専用 LAN ポートを搭載しています。プロセッサー温度やファン回転数の監視、リモートでサーバの電源制御などができ、遠隔地やサーバールームに設置したワークステーションのメンテナンスが可能です。
ワークステーション管理者が稼動状況を確認でき、障害発生時にワークステーションの起動・再起動などをリモートできるため、運用コストの大幅な低減を実現します。

耐久性とパフォーマンス を兼ね備えた 高速ストレージ SSD

TLC インテル® 3D NAND テクノロジーを採用した大容量 SSD でデータセンターのラック当たり保存データ量を増やすことができます。サーバーの設置面積を広げずに HDD よりも有利な SSD のパフォーマンスが手に入ります。
HDD に比べて年間故障率 (AFR) が 3.2 倍低い1ため、IT 部門はストレージデバイスの置き換えやアップグレードに費やす時間と費用が軽減できます。HDD に比べて年間故障率 (AFR) が 3.2 倍低いため、IT 部門はストレージデバイスの置き換えやアップグレードに費やす時間と費用が軽減できます。
24 時間 365 日稼働を想定したエンタープライズ・クラス・ストレージ
最大 200 万時間の MTBF の Exos(エグゾス) 7E2000 ハードディスク・ドライブは、最も要求の厳しいストレージ環境で 24 時間 365 日常時稼働の信頼性と耐久性を発揮します。
大量のデータへの安全なアクセスが必要とされるインフラストラクチャ向けに、実績のある 2.5 インチ・フォーム・ファクタでデータ・センターのフットプリントを最適化します。データ環境を活性化させる Exos 7E2000 があれば、データ・センター設計者や IT プロフェッショナルは、厳しい常時稼働向けに信頼できるパフォーマンス、高い信頼性、強力なセキュリティを実現することができます。
200 万時間の MTBF を誇り、550TB/年の作業負荷に対応します。密度の高いデータ・ストレージ と低消費電力によって、TCO を削減しながら、ストレージの SLA を満たします。

最大 24 基 フロント・ホットスワップ対応

最大 24 基の 2.5 インチ・ストレージを搭載でき、マウンターを利用することで 2.5 インチ・ストレージも搭載可能です。
また、全てのベイで、ホットスワップに対応していますので、RAID 構成ストレージで障害が発生した場合などでも、運用を止めずにストレージの交換ができます。
高効率 80 Plus Titanium 認証電源
コンピューターやサーバーの電源が 20% ~ 100% の負荷環境下において、電源交換効率 80% 以上がスタンダードという基準に対して、80 Plus Titanium は、92% 以上 (20% 負荷時)、94% 以上 (50% 負荷時)、90% 以上 (100% 負荷時) の効率性を発揮する電源ユニットを標準採用しています。
電力変換効率の向上した電源ユニットは、発熱の減少によって冷却ファンの回転数の低下による静音化や電子部品の劣化低減が可能になり、コンピュータの快適性や省電力性の向上と同時に製品寿命も伸びます。

| モデル名 | APPLIED CERVO Deep for Linux Type-DP4U8QR | |
| 外形寸法 | 約 (W)437 x (D)737 x (H)178 mm | |
| ※4U ラック・マウント | ||
| オペレーティング システム |
標準 | Ubuntu 18.04 LTS 64bit ※インストール代行 |
| その他 | USB リカバリ・ディスク付属 | |
| 統合開発環境 | CUDA 10 | |
| Python 2.7.15rc1, 3.6.7 | ||
| Tensor Flow 1.12.0 | ||
| Keras 2.2.4 | ||
| Chainer 5.2.0 | ||
| Pytorch 1.1.0 | ||
| OpenCV Use CUDA 4.0.1 | ||
| cuDNN 7.3.1 | ||
| NCCL 2.3.7 | ||
| FFmpeg 3.4.4 | ||
| Oracle-JAVA8 build 1.8.0_192 | ||
| Keras 2.2.4 | ||
| 電源ユニット | 定格出力 | 2,000W (200V 時) | 1,000W (100V 時) |
| ユニット数 | 2 基 | |
| 仕様 | 80 Plus Titanium 認証 | 冗長化仕様 | |
| チップ・セット | 名称 | インテル® C622 チップ・セット |
| PCI Express 最大レーン数 |
20 レーン | |
| セキュリティ・チップ | 非搭載 | |
| GPU (計算用) | 名称 | NVIDIA® Quadro® GP100 |
| 搭載数 | 8 基 | |
| 最大搭載数 | 8 基 | |
| CUDA コア数 | 3584 コア (1GPU あたり) | |
| メモリー | 16GB | HBM2 (1GPU あたり) | |
| 半精度 浮動小数点性能 |
20.7TFLOPS (1GPU あたり) | |
| 単精度 浮動小数点性能 |
10.3TFLOPS (1GPU あたり) | |
| Tensor 演算性能 |
5.2TFLOPS (1GPU あたり) | |
| プロセッサー | 名称 | インテル® Xeon® Silver 4110 プロセッサー |
| プロセッサー数 | 2 基 | |
| 動作周波数 | 2.1GHz | Max 3.0GHz | |
| コア数 | 8 コア | 16 スレッド (1CPU あたり) | |
| L3 キャッシュ | 11MB (1CPU あたり) | |
| PCI Express 最大レーン数 |
48 レーン (1CPU あたり) | |
| その他 | Skylake | |
| プロセッサー・ファン | 2U Active CPU Heat Sink | |
| メモリー | 標準 | 192GB (16GBx12) |
| 最大容量 | 3DS-RDIMM:6TB | |
| 3DS-LRDIMM:6TB | ||
| スロット数 | 24 スロット (空き:12 スロット) | |
| 仕様 | DDR4-2666 | Registered-ECC | CPU により DDR4-2400 で駆動 | |
| チャンネル数 | 6 チャンネル | 最大 6 チャンネル (1CPU あたり) | |
| ストレージ (標準) | 容量 | 480GB |
| 規格 | SATA3 | SSD | 耐久仕様 | |
| 読み出し (シーケンシャル) |
500MB/s | |
| 書き込み (シーケンシャル) |
330MB/s | |
| TBW (総書込みバイト量) |
900TB | |
| MTBF (平均故障間隔) |
200 万時間 | |
| ストレージ (増設) | 容量 | 12TB (2TB x 8) | RAID6 |
| 規格 | SATA3 | HDD | 高耐久仕様 | |
| 回転数 | 7,200rpm | |
| キャッシュ | 128MB | |
| MTBF (平均故障間隔) |
200 万時間 | |
| 対応 RAID 機能 (SATA) | RAID 0/1/5/6/10/50/60 | AOC-S3108L-H8IR-16DD | |
| ※マザーボードの搭載機能です。 | ||
| ※OS により対応状況が異なります。 | ||
| 光学ドライブ | 非搭載 | |
| グラフィック | 名称 | ASPEED AST2500 BMC |
| メモリー | - | |
| ポート | D-Sub:1 ポート | |
| 最大画面出力 | 最大 1 画面出力 | |
| サウンド | 仕様 | 非搭載 |
| チャンネル | - | |
| ネットワーク | 名称 | インテル® 10GBase-T LAN |
| インターフェイス | 10GBASE-T | 1000BASE-T | |
| ポート数 | 2 ポート | |
| IPMI | 名称 | Intelligent Platform Management Interface v.2.0 |
| ポート数 | 1 ポート | |
| 各種ポート | USB | USB3.0:4 ポート (前:0 ポート | 背:4 ポート) |
| その他 | - | |
| 拡張ソケット | - | |
| 拡張スロット | 1 PCI-E 3.0 x16 (FH, FL) slots | |
| 1 PCI-E 3.0 x8 (FH, FL, in x16) slot | ||
| ドライブ・ベイ | 2.5 インチ (HotSwap 対応 | SAS/SATA):24 ベイ | |
| 入力機器 | キーボード | 非搭載 |
| マウス | 非搭載 | |
| ラックマウント | サイズ | 19 インチ | 4U ラックマウント |
| レール・キット | 付属 | |
| 保証 | 期間 | 3 年間 |
| 方式 | センドバック方式ハードウェア保証 | |







業務に強いPCシリーズ






おすすめサービス














ビジネス・スタンダード PC

モニターの背面に取り付け可能

業務用途から開発・制御用途で活躍

CAD/CAM/CAE 用途で活躍

専門性を追求したファクトリー向けPC

お客様の業務を安定継続させるPC

データを護る特別設計











